Warum Nachhaltigkeit eine strategische Notwendigkeit ist
Nachhaltigkeit ist längst kein reines Umwelt- oder Image-Thema mehr – sie ist ein zentraler Erfolgsfaktor für Unternehmen. Besonders der Mittelstand steht vor steigenden Anforderungen: Regulierungen, steigende Energiekosten und veränderte Kundenerwartungen fordern ein Umdenken. Eine klare Nachhaltigkeitsstrategie hilft, Risiken zu minimieren, Kosten zu senken und sich Wettbewerbsvorteile zu sichern. Doch wo beginnt man? Ein strukturierter Prozess schafft Orientierung.
Der Fahrplan zur nachhaltigen Transformation
1. Motivation klären – Warum Nachhaltigkeit?
Der erste Schritt ist die Frage nach dem „Warum“. Unternehmen entwickeln eine Nachhaltigkeitsstrategie aus unterschiedlichen Beweggründen:
- Rechtliche Vorgaben: Die EU-Taxonomie, das Lieferkettensorgfaltspflichtengesetz (LkSG) und die Corporate Sustainability Reporting Directive (CSRD) machen nachhaltiges Handeln zur Pflicht. Wer früh handelt, bleibt zukunftssicher.
- Kundenanforderungen: Nachhaltigkeit wird zunehmend zur Erwartung – besonders bei B2B-Kunden, die eigene ESG-Kriterien erfüllen müssen.
- Wirtschaftliche Vorteile: Ressourceneffizienz spart Kosten. Wer weniger Energie verbraucht oder Materialien wiederverwertet, steigert seine Profitabilität.
- Unternehmenswerte: Viele Mittelständler sind familiengeführt und denken langfristig. Nachhaltigkeit sichert die Zukunftsfähigkeit des Unternehmens und stärkt die Arbeitgebermarke.
Beispiel: Ein Maschinenbauunternehmen entscheidet sich für Nachhaltigkeit, weil große Automobilhersteller zunehmend klimaneutrale Zulieferer bevorzugen. Durch eine frühzeitige CO₂-Reduktionsstrategie sichert es sich langfristige Aufträge.
2. Verantwortlichkeiten definieren – Wer ist zuständig?
Nachhaltigkeit ist eine Querschnittsaufgabe. Erfolgreiche Unternehmen setzen auf ein Nachhaltigkeitsteam mit festen Zuständigkeiten.
- Geschäftsführung: Gibt die strategische Richtung vor und sorgt für Budget und Ressourcen.
- Nachhaltigkeitsmanager: Koordiniert Maßnahmen und behält den Überblick.
- Einkauf: Setzt nachhaltige Beschaffungsrichtlinien um.
- Produktion: Optimiert Prozesse zur Ressourcenschonung.
- Marketing & Vertrieb: Kommuniziert Nachhaltigkeitsmaßnahmen an Kunden und Stakeholder.
Beispiel: Ein mittelständisches Textilunternehmen bildet ein Nachhaltigkeitsteam mit Mitarbeitenden aus Einkauf, Produktion und HR. Sie führen eine nachhaltige Materialstrategie ein, optimieren die Lieferkette und entwickeln Schulungen für das Personal.
3. Bestandsanalyse – Wo stehen wir?
Ein Unternehmen muss zunächst verstehen, welche nachhaltigkeitsrelevanten Ressourcen und Prozesse bereits existieren.
- Energieverbrauch: Wo entstehen die größten Emissionen?
- Materialeinsatz: Gibt es Recycling- oder Wiederverwendungsoptionen?
- Datenmanagement: Sind Umweltkennzahlen bereits messbar?
- Lieferketten: Welche Nachhaltigkeitsstandards gelten für Lieferanten?
Beispiel: Ein Produktionsbetrieb analysiert seinen Energieverbrauch und erkennt, dass veraltete Maschinen hohe Stromkosten verursachen. Durch den Einsatz energieeffizienter Anlagen sinkt der Verbrauch um 20 %.
4. Stakeholderanalyse – Wen betrifft es?
Nachhaltigkeit betrifft verschiedene Interessensgruppen. Unternehmen sollten ihre Erwartungen verstehen:
- Kunden: Fordern nachhaltige Produkte und Transparenz.
- Mitarbeitende: Wollen nachhaltige Arbeitsbedingungen und sinnstiftende Tätigkeiten.
- Investoren: Achten zunehmend auf ESG-Kriterien.
- Lieferanten: Müssen nachhaltige Standards einhalten.
Beispiel: Ein Möbelhersteller führt Umfragen unter seinen Kunden durch und erfährt, dass langlebige, reparierbare Produkte stark nachgefragt werden. Als Reaktion entwickelt er eine neue Produktlinie mit austauschbaren Komponenten.
5. Wesentlichkeitsanalyse – Was ist wirklich relevant?
Nicht jedes Nachhaltigkeitsthema ist für jedes Unternehmen gleichermaßen wichtig. Eine Wesentlichkeitsanalyse hilft, sich auf die Themen mit dem größten Einfluss zu konzentrieren.
- Ökologische Themen: Energieeffizienz, Emissionsreduktion, Kreislaufwirtschaft
- Soziale Themen: Arbeitsbedingungen, Diversität, Gesundheitsschutz
- Ökonomische Themen: Nachhaltige Lieferketten, Innovationspotenziale
Beispiel: Ein Logistikunternehmen erkennt durch seine Wesentlichkeitsanalyse, dass der größte Einfluss in der Dekarbonisierung der Fahrzeugflotte liegt. Es setzt auf Elektrofahrzeuge und klimafreundliche Routenplanung.
6. Nachhaltigkeitsstrategie entwickeln – Ziele und Maßnahmen definieren
Eine klare Strategie sollte messbare Ziele und konkrete Maßnahmen enthalten. Die SMART-Formel hilft dabei:
- Spezifisch: Klare Zielformulierung („CO₂-Ausstoß um 30 % reduzieren“)
- Messbar: Datenbasiert überprüfbar (Energieverbrauch pro Produkt)
- Attraktiv: Wirtschaftlich sinnvoll und umsetzbar
- Realistisch: An aktuelle Ressourcen angepasst
- Terminiert: Klare Deadlines zur Umsetzung
Mögliche Maßnahmen:
- Materialkreisläufe schließen: Einführung von Recyclingkonzepten
- Erneuerbare Energien nutzen: Photovoltaik auf Unternehmensgebäuden
- Digitale Lösungen einsetzen: KI zur Energieoptimierung
Beispiel: Ein Unternehmen aus der Chemiebranche definiert als Ziel, den Wasserverbrauch um 40 % zu senken. Es installiert geschlossene Kreislaufsysteme und spart jährlich Millionen Liter Wasser.
7. Umsetzung und Weiterentwicklung – Nachhaltigkeit dauerhaft verankern
Nachhaltigkeit ist kein einmaliges Projekt, sondern ein langfristiger Prozess. Die besten Strategien scheitern ohne klare Umsetzung.
- Regelmäßige Fortschrittskontrollen (z. B. jährlicher Nachhaltigkeitsbericht)
- Mitarbeitende aktiv einbinden (Workshops, Schulungen, Vorschlagswesen)
- Erfolge kommunizieren (intern und extern)
Beispiel: Ein Maschinenbauunternehmen führt einen internen Nachhaltigkeitspreis ein. Mitarbeitende können Ideen einreichen, um Prozesse nachhaltiger zu gestalten.
Nachhaltigkeit als Wettbewerbsvorteil nutzen
Nachhaltige Unternehmen sind resilienter, effizienter und innovativer. Wer frühzeitig handelt, sichert sich einen Vorsprung – wirtschaftlich und ökologisch. Eine klare Nachhaltigkeitsstrategie hilft, Risiken zu minimieren, Kosten zu senken und neue Geschäftsmöglichkeiten zu erschließen.
- Reduzierte Kosten: Weniger Energie- und Materialverbrauch
- Höhere Attraktivität: Kunden und Mitarbeitende schätzen nachhaltige Unternehmen
- Zukunftssicherheit: Regulierungen und Marktveränderungen frühzeitig adressieren
Der Mittelstand kann durch eine systematische Nachhaltigkeitsstrategie langfristige Vorteile realisieren. Wer frühzeitig beginnt, verschafft sich einen echten Wettbewerbsvorteil in einer nachhaltigen Zukunft!
Technologien wie Künstliche Intelligenz bringen viele Fachbegriffe und Ausdrucksweisen mit sich, die für Nicht-Profis eine Hürde darstellen können. Um sich einem komplexen Thema zu nähern, ist ein Verständnis der Begrifflichkeiten unabdingbar. Im Nachfolgenden finden Sie daher eine ausführliche Auflistung der gängigsten Begriffe mit kurzen leicht verständlichen Erklärungen von unseren KI-Trainer:innen.
Tipp: Suchen Sie ein bestimmtes Wort, geben Sie es in die Suchfunktion Ihres Browsers ein.
Vermissen Sie einen Begriff? Schreiben Sie uns!
Inhaltsverzeichnis
1. Grundbegriffe
Künstliche Intelligenz (KI) / Artificial Intelligence (AI):
Das breite Feld, das sich mit der Entwicklung von Maschinen beschäftigt, die Aufgaben ausführen können, die normalerweise menschliche Intelligenz erfordern, wie z.B. das Erkennen, Lernen und Problemlösen.
Maschinelles Lernen / Machine Learning (ML):
Ein Teilbereich der KI, der sich auf die Entwicklung von Algorithmen konzentriert, die es Computern ermöglichen, aus Daten zu lernen und Vorhersagen zu treffen.
Deep Learning:
Ein Teilbereich des maschinellen Lernens, der neuronale Netzwerke mit vielen Schichten (daher „tief“) verwendet, um komplexe Muster in großen Datensätzen zu modellieren.
Generative KI / Generative AI:
Eine Art von KI, die in der Lage ist, neue Inhalte (Text, Bilder, Musik) basierend auf den Daten zu erstellen, auf denen sie trainiert wurde, wie z.B. GPT für Text oder DALL-E für Bilder.
Verarbeitung natürlicher Sprache / Natural Language Processing (NLP):
Ein Bereich der KI, der sich auf die Interaktion zwischen Computern und Menschen durch natürliche Sprache konzentriert und Aufgaben wie Übersetzung, Sentimentanalyse und Texterstellung ermöglicht.
Bildverarbeitung / Computer Vision:
Ein Bereich der KI, der darauf abzielt, Maschinen zu befähigen, visuelle Informationen aus der realen Welt zu interpretieren und zu verstehen, wie z. B. das Erkennen und Klassifizieren von Objekten in Bildern.
Klassifikation:
Eine Art von überwachten Lernproblems, bei dem das Ziel darin besteht, Eingabedaten in eine von mehreren vordefinierten Kategorien einzuordnen.
Regression:
Ein überwachter Lernansatz, bei dem das Ziel ist, einen kontinuierlichen Wert vorherzusagen, basierend auf Eingabedaten. Beispiel: Vorhersage des Preises eines Hauses.
Black Box:
Ein Begriff, der ein Modell beschreibt, dessen interne Funktionsweise schwer nachvollziehbar ist. Dies trifft oft auf komplexe Modelle wie tiefe neuronale Netzwerke zu.
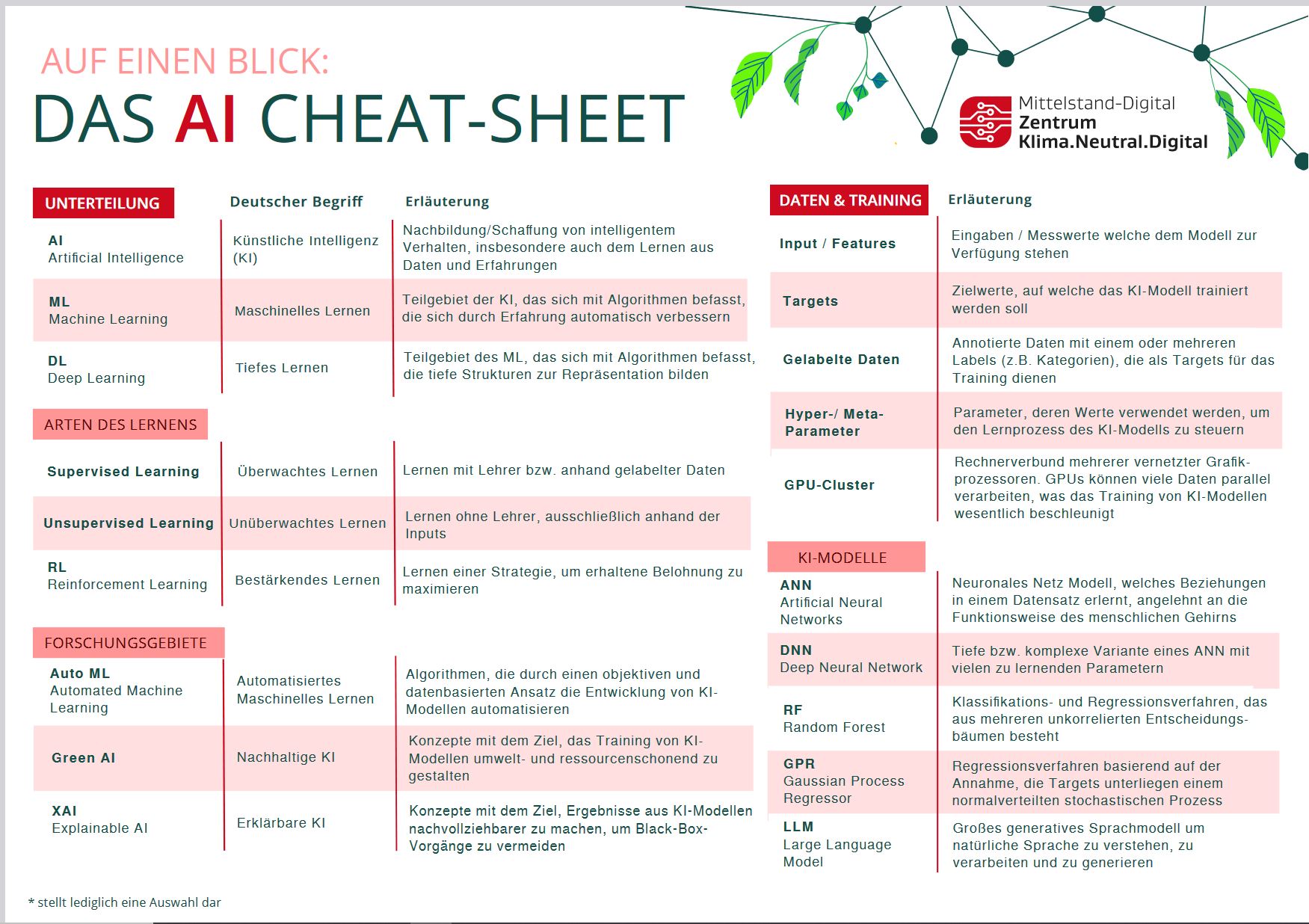
2. Lernarten
Überwachtes Lernen / Supervised Learning:
Eine Art des maschinellen Lernens, bei dem das Modell auf gelabelten Daten trainiert wird, was bedeutet, dass jedes Trainingsbeispiel mit einer zugehörigen richtigen Antwort versehen ist.
Unüberwachtes Lernen / Unsupervised Learning:
Eine Art des maschinellen Lernens, bei dem das Modell auf Daten ohne explizite Labels trainiert wird. Das Modell versucht selbstständig, Muster oder Strukturen in den Daten zu erkennen. Ein typisches Beispiel ist das Gruppieren von ähnlichen Daten.
Verstärkendes Lernen / Reinforcement Learning:
Ein Lernparadigma, bei dem ein Agent durch Interaktionen mit einer Umgebung lernt. Der Agent erhält basierend seiner ausgeführten Aktionen Belohnungen oder Strafen und lernt so Stück für Stück, seine Strategie entsprechend zu verbessern.
3. Modelle und Algorithmen
Diskriminator:
Ein Modell, das in Generative Adversarial Networks (GANs) verwendet wird, um echte Daten von durch einen Generator erzeugten gefälschten Daten zu unterscheiden.
Generator:
Ein Modell in einem GAN, das darauf trainiert wird, Daten zu erzeugen, die dem realen Datensatz ähneln. Der Generator versucht, den Diskriminator zu täuschen.
Parametrisches Modell:
Ein Modell, das eine feste Anzahl von Parametern hat, die unabhängig von der Menge der Trainingsdaten ist. Beispiele sind lineare Regression oder logistische Regression.
Nicht-Parametrisches Modell:
Ein Modell, das keine feste Anzahl von Parametern hat und seine Komplexität an die Menge der Trainingsdaten anpasst. Beispiele sind K-Nearest Neighbors (K-NN) oder Decision Trees.
Ensemble Methoden:
Techniken, bei denen mehrere Modelle kombiniert werden, um die Leistung zu verbessern. Beispiele sind Random Forests oder Gradient Boosting.
Variational Autoencoder (VAE):
Eine Art von Autoencoder, die probabilistische Modelle verwendet, um Eingabedaten zu rekonstruieren und gleichzeitig latente Variablen zu lernen, um die Datenverteilung zu modellieren.
BERT (Bidirectional Encoder Representations from Transformers):
Ein leistungsstarkes Sprachmodell, das bidirektionale Kontextinformationen verwendet, um präzisere Textdarstellungen für Aufgaben wie Frage-Antwort-Systeme und Textklassifikation zu erzeugen.
Bidirektionale Kontextinformationen:
Ein Konzept, bei dem Informationen aus dem Kontext sowohl in vorwärts- als auch in rückwärtsgerichteten Richtungen verarbeitet werden, um eine umfassendere Darstellung der Daten zu erzeugen. Häufig verwendet in Modellen wie bidirektionalen RNNs oder BERT.
Generative Pre-trained Transformer (GPT):
Ein Sprachmodell, das auf einer großen Textmenge vortrainiert wird, um menschenähnlichen Text zu generieren und für eine Vielzahl von Aufgaben der natürlichen Sprachverarbeitung verwendet wird.
Neuronale Netzwerke / Neural Networks:
Computermodelle, die vom menschlichen Gehirn inspiriert sind und aus Schichten von miteinander verbundenen Knoten (Neuronen) bestehen, die Daten auf komplexe Weise verarbeiten.
Künstliches Neuronales Netzwerk (KNN) / Artificial Neural Network (ANN):
Eine Art neuronales Netzwerk mit einer oder mehreren Schichten. Es ist der grundlegende Baustein des Deep Learning.
Tiefes Neuronales Netzwerk (TNN) / Deep Neural Network (DNN):
Ein KNN mit mehreren verborgenen Schichten zwischen der Eingabe- und Ausgabeschicht. Diese werden verwendet, um komplexe Datenmuster zu modellieren.
Convolutional Neural Network (CNN):
Eine Art tiefes neuronales Netzwerk, das sich besonders gut für die Verarbeitung von gitterartigen Daten wie Bildern eignet. Es verwendet Faltungsschichten, um automatisch Merkmale wie Kanten und Texturen zu erkennen.
Rekurrentes Neuronales Netzwerk / Recurrent Neural Network (RNN):
Ein neuronales Netzwerk, das für die Verarbeitung sequenzieller Daten entwickelt wurde, indem es Informationen über Zeiträume hinweg speichert und verarbeitet, wie z.B. bei der Text- oder Spracherkennung.
Transformer:
Eine moderne Architektur für neuronale Netzwerke, die vor allem in NLP verwendet wird und sich durch die Fähigkeit auszeichnet, parallele Verarbeitung und Selbstaufmerksamkeit (self-attention) zu nutzen, wie z. B. bei Modellen wie GPT und BERT.
Graph Neural Network (GNN):
Ein neuronales Netzwerk, das speziell für die Arbeit mit Graphdaten entwickelt wurde, wie z.B. soziale Netzwerke oder Molekularstrukturen.
Autoencoder:
Eine spezielle Art von neuronalen Netzwerken, die verwendet wird, um effiziente Kodierungen von Daten zu lernen, oft für Aufgaben wie Dimensionenreduktion oder Anomalieerkennung.
Generatives Adversariales Netzwerk / Generative Adversarial Network (GAN):
Ein Paar von neuronalen Netzwerken, die gegeneinander antreten: ein Generator, der versucht, realistische Daten zu erstellen, und ein Diskriminator, der versucht, echte von generierten Daten zu unterscheiden.
Retrieval-Augmented Generation (RAG):
Eine Technik, die generative Modelle systematisch mit Kontextinformationen aus einer oder mehreren Datenbanken anreichert, um präzisere und informativere Antworten zu generieren. Dabei wird die ursprüngliche Eingabe durch besonders passende Kontextinformationen angereichert, bevor die Antwort durch das LLM generiert wird.
Gaussian Process Regression (GRP):
Ein nicht-parametrisches Modell zur Regression, das verwendet wird, um Vorhersagen mit Unsicherheitsabschätzungen zu machen.
Random Forest (RF):
Ein Ensemble-Lernverfahren, das viele Entscheidungsbäume trainiert und deren Ergebnisse kombiniert, um robustere und genauere Vorhersagen zu machen.
Große Sprachmodelle / Large Language Model (LLM):
Ein tiefes neuronales Netzwerk, das auf großen Mengen von Textdaten trainiert wurde und in der Lage ist, natürliche Sprache zu generieren, wie z. B. GPT-3.
Automatisiertes Maschinelles Lernen / Automated Machine Learning (AutoML):
Der Prozess der Automatisierung der Anwendung von maschinellem Lernen auf reale Probleme. AutoML umfasst die automatische Auswahl von Modellen, Hyperparametertuning und Modellbewertung.
SVM (Support Vector Machine):
Ein überwachter Lernalgorithmus, der sowohl für Klassifikations- als auch für Regressionsaufgaben verwendet wird und darauf abzielt, die bestmögliche Trennlinie (oder Hyperebene) zwischen Klassen zu finden.
k-NN (k-Nearest Neighbors):
Ein einfacher, nicht-parametrischer Algorithmus, der für Klassifikations- und Regressionsaufgaben verwendet wird und Vorhersagen auf Basis der K-ähnlichsten Datenpunkte im Trainingssatz trifft.
LSTM (Long Short-Term Memory):
Ein spezieller Typ von Rekurrenten Neuronalen Netzwerken (RNNs), der entworfen wurde, um das Problem des Langzeitgedächtnisses zu lösen. LSTMs können wichtige Informationen über lange Zeitspannen hinweg speichern und abrufen.
Hauptkomponentenanalyse / PCA (Principal Component Analysis):
Eine Technik zur Dimensionenreduktion, die darauf abzielt, die Varianz in einem Datensatz durch Transformation auf eine kleinere Anzahl von Dimensionen zu maximieren.
Entscheidungsbaum / Decision Tree:
Ein Modell, das Daten in Form eines baumartigen Diagramms darstellt und auf Basis von Entscheidungen (Knoten) und Resultaten (Blättern) Vorhersagen trifft. Häufig verwendet für Klassifikations- und Regressionsaufgaben.
AdaBoost / AdaBoost:
Ein Ensemble-Lernverfahren, das mehrere schwache Klassifikatoren kombiniert, um einen starken Klassifikator zu erstellen. Es gewichtet falsch klassifizierte Datenpunkte stärker, um die Modellgenauigkeit zu verbessern.
Gradient Boosting / Gradient Boosting:
Ein weiteres Ensemble-Lernverfahren, das sequentiell Modelle trainiert, wobei jedes Modell die Fehler der vorherigen Modelle korrigiert.
K-Means / K-Means:
Ein Algorithmus für unüberwachtes Lernen, der Daten in K-Cluster unterteilt, wobei jede Datenpunkt dem Cluster mit dem nächsten Mittelwert zugewiesen wird.
Hierarchisches Clustering / Hierarchical Clustering:
Ein unüberwachter Lernalgorithmus, der eine hierarchische Struktur von Clustern erstellt, indem er Datenpunkte schrittweise zusammenfasst oder teilt. Auf diese Weise werden Gruppen (Cluster) aus Daten gebildet, die sich in ihren Strukturen ähneln. Wie diese Ähnlichkeit genau definiert wird, ist dem Algorithmus überlassen.
Selbstaufmerksamkeit / Self-Attention:
Self-Attention ist ein Mechanismus, der beim maschinellen Lernen, insbesondere bei der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) und bei Computer-Vision-Aufgaben, verwendet wird, um Abhängigkeiten und Beziehungen in Eingabesequenzen zu erfassen. Es ermöglicht dem Modell, die Bedeutung verschiedener Teile der Eingabesequenz zu erkennen und zu gewichten, indem es sich selbst beobachtet.
Einbettungsschicht / Embedding Layer:
Eine Art von Hiddel Layer (versteckter Schicht) in einem neuronalen Netzwerk. Diese Art von Layer ordnet Eingabedaten von einem hochdimensionalen in einen niedrigdimensionalen Raum ein, wodurch das Netz mehr über die Beziehung zwischen den einzelnen Eingaben lernt und die Daten effizienter verarbeiten kann.
Eingabeschicht:
Die erste Schicht eines neuronalen Netzes, die die Eingabedaten entgegennimmt und an die nächsten Schichten weiterleitet. Sie repräsentiert die Rohdaten, die dem Modell zugeführt werden.
Ausgabeschicht:
Die letzte Schicht eines neuronalen Netzes, die das finale Ergebnis des Modells liefert, wie z.B. eine Klassifizierung oder eine Vorhersage.
Faltungsschichten (Convolutional Layers):
Schichten in einem neuronalen Netz, die Faltungsoperationen durchführen, um Merkmale aus den Eingabedaten zu extrahieren. Besonders wichtig in Convolutional Neural Networks (CNNs) für die Bildverarbeitung.
4. Daten und Vorverarbeitung
Datenverteilung:
Die Verteilung der Werte in einem Datensatz, die wichtige Informationen über die Struktur und das Verhalten der Daten liefert.
Latente Variablen:
Nicht direkt beobachtbare Variablen, die in einem Modell verwendet werden, um zugrunde liegende Strukturen oder Muster in den Daten zu repräsentieren.
Epoche / Epoch:
Ein vollständiger Durchlauf durch den gesamten Trainingsdatensatz während des Lernprozesses.
Batch-Größe / Batch Size:
Die Anzahl der Trainingsbeispiele, die in einer Iteration des Modelltrainings verwendet werden.
Eingabedaten / Features:
Eingaben (oder Merkmale) sind die Variablen oder Attribute, die zur Vorhersage verwendet werden. Beispielsweise könnten bei der Vorhersage von Hauspreisen die Merkmale die Größe, der Standort und die Anzahl der Schlafzimmer sein.
Beschriftete Daten / Labeled Data:
Dabei handelt es sich um Datensätze, die neben den Daten, die als Eingabedaten fungieren auch auch die entsprechende Ausgabe (Label) enthalten. Dies ist für das Training von überwachten Lernmodellen unerlässlich.
Ziele / Targets:
Die Ausgaben oder Labels, die das Modell vorhersagen soll. Zum Beispiel könnte bei einem Spam-Erkennungssystem das Ziel darin bestehen, festzustellen, ob eine E-Mail Spam ist oder nicht.
Lernrate:
Ein Hyperparameter, der die Schrittgröße steuert, mit der ein Modell seine Parameter während des Trainings anpasst. Eine zu hohe oder zu niedrige Lernrate kann die Leistung des Modells beeinträchtigen.
Hidden Layer:
Die Schichten in einem neuronalen Netzwerk, die zwischen der Eingabe- und der Ausgabeschicht liegen. Diese Schichten transformieren die Eingaben durch nicht-lineare Funktionen.
Synthetische Daten / Synthetic Data:
Künstlich erzeugte Daten, die zum Trainieren von Modellen verwendet werden. Synthetische Daten werden häufig dann verwendet, wenn echte Daten knapp oder sensibel sind. Synthetische Daten bergen aber auch ein gewisses Risiko was die Datenqualität angeht.
Datenaugmentation / Data Augmentation:
Techniken, die zur Erhöhung der Vielfalt der Trainingsdaten ohne Erhebung neuer Daten eingesetzt werden, oft durch Transformation vorhandener Daten, wie z. B. durch Rotieren von Bildern. Es werden also bestehende Daten verwendet und dann abgeändert, um dem Modell im Traning eine größere Varianz an Daten geben zu können.
Datenimputation / Data Imputation:
Der Prozess des Auffüllens fehlender Daten mit Ersatzwerten, um die Integrität eines Datensatzes zu erhalten.
Tokenisierung / Tokenization:
Der Prozess der Umwandlung von Text in kleinere Einheiten (Tokens), wie Wörter oder Unterwörter, zur Verarbeitung in NLP-Modellen. Texte werden also in kleinere Stücke unterteilt, um sie maschinell besser verarbeitbar zu machen.
Wort-Einbettung / Word Embedding:
Eine Darstellung von Text, bei der Wörter in Vektoren in einem kontinuierlichen Vektorraum abgebildet werden, um die semantische Bedeutung zu erfassen. Auf diese Weise können die Beziehungen von Wörtern wie Ähnlichkeit oder Zusammenhang abgebildet werden.
Selbstaufmerksamkeit (Self-Attention):
Ein Mechanismus, der es einem Modell ermöglicht, verschiedene Teile einer Eingabesequenz unterschiedlich zu gewichten, basierend auf ihrer Bedeutung. Dies ist zentral für Transformer-Modelle und ermöglicht es, komplexe Abhängigkeiten in den Daten zu erfassen.
Graphdaten:
Strukturelle Daten, die als Knoten und Kanten in einem Graphen dargestellt werden. Sie kommen oft in Netzwerken oder Beziehungen zwischen Entitäten vor und werden in Graph Neural Networks (GNNs) verarbeitet.
Datenkodierung:
Der Prozess der Umwandlung von Rohdaten in ein Format, das für maschinelle Lernmodelle geeignet ist. Dies kann die Transformation von kategorischen Daten in numerische Werte oder die Normalisierung von Daten umfassen.
Prompt:
Eine kurze Eingabe oder ein Text, der einem Modell gegeben wird, um eine spezifische Aufgabe auszuführen oder eine bestimmte Ausgabe zu erzeugen. In der Verarbeitung natürlicher Sprache ist der Prompt der Text, der die gewünschte Aktion auslöst.
Dimensionsreduktion:
Ein Verfahren, um die Anzahl der Zufallsvariablen unter Berücksichtigung der wichtigsten Informationen zu verringern. Methoden wie PCA (Principal Component Analysis) werden verwendet, um die Komplexität der Daten zu reduzieren.
5. Optimierung und Tuning
Optimierung / Optimization:
Der Prozess der Anpassung der Modellparameter zur Minimierung der Verlustfunktion, typischerweise durch Techniken wie den Gradientenabstieg.
Tuning:
Der Prozess der Anpassung der Hyperparameter eines Modells, um dessen Leistung zu optimieren.
Hyperparameter:
Einstellungen oder Konfigurationen, die vor Beginn des Trainingsprozesses festgelegt werden, wie z.B. die Lernrate oder die Anzahl der Schichten in einem neuronalen Netzwerk. Sie müssen feinjustiert werden, um die Modellleistung zu verbessern.
Metaparameter:
Hyperparameter, die die Konfiguration anderer Hyperparameter steuern. Sie werden oft verwendet, um den eigentlichen Tuning-Prozess der Hyperparameter zu variieren.
Gradientenabstieg / Gradient Descent:
Ein Optimierungsalgorithmus, der verwendet wird, um die Verlustfunktion zu minimieren, indem die Hyperparameter schrittweise angepasst werden.
Bayessche Optimierung / Bayesian Optimization:
Ein Ansatz zur Optimierung komplexer, teurer und nicht-linearer Funktionen, oft verwendet zur Feinabstimmung von Hyperparametern in maschinellen Lernmodellen.
Evolutionäre Algorithmen / Evolutionary Algorithms:
Optimierungstechniken, die von der natürlichen Evolution inspiriert sind und Mechanismen wie Mutation, Selektion und Kreuzung nutzen, um Lösungen für Probleme zu finden.
6. Evaluierung und Metriken
Metriken / Metrics:
Kennzahlen zur Bewertung der Leistung von Modellen, wie z. B. Genauigkeit, Präzision, Recall und F1-Score.
Verlust / Loss:
Ein Maß dafür, wie gut (oder schlecht) die Vorhersagen eines Modells mit den tatsächlichen Daten übereinstimmen. Ein niedrigerer Loss weist auf eine bessere Modellleistung hin.
Train/Test-Aufteilung / Train/Test Split:
Die Aufteilung eines Datensatzes in zwei Teile: einen zum Trainieren des Modells und einen zum Testen seiner Leistung. Dies hilft, die Fähigkeit des Modells zu bewerten, auf neue, unbekannte Daten zu verallgemeinern. Das heißt auf basis der Trainingsdaten lernt das Modell die Daten kennen und auf den Testdaten, die dem Modell unbekannt sind, wird überprüft, ob es tatsächlich allgemein gültige Muster gelernt hat.
Genauigkeit / Accuracy:
Eine Metrik, die den Prozentsatz aller korrekten Vorhersagen eines Modells von allen getätigten Vorhersagen angibt. Häufig bei Klassifikationsaufgaben verwendet. Also der Anteil aller Vorhersagen, die korrekt sind.
Präzision / Precision:
Eine Metrik, die den Anteil der tatsächlichen positiven Vorhersagen unter allen als positiv klassifizierten Vorhersagen des Modells angibt. Also wie viel Prozent der als positiv vorhergesagten Werte sind tatsächlich positiv.
Recall:
Eine Metrik, die den Anteil der tatsächlichen positiven Vorhersagen unter allen positiven Fällen in den Daten misst. Wie viel Pozent der positiven Fälle wurden also vom Modell richtig als positiv vorhergesagt.
F1-Score:
Eine Metrik, die Precision und Recall ausbalanciert und eine einzige Kennzahl liefert, die sowohl falsche Positive als auch falsche Negative berücksichtigt.
Überanpassung / Overfitting:
Eine Situation, in der ein Modell sehr gut auf Trainingsdaten performt, aber Schwierigkeiten hat, auf neue, ungesehene Daten zu generalisieren. Das heißt, dass das Modell sich zu stark an die Trainingsdaten angepasst hat und dementsprechend weniger gut auf davon abweichenden Testdaten performt.
Unteranpassung / Underfitting:
Wenn ein Modell zu einfach ist, um die zugrunde liegende Struktur der Daten zu erfassen, was zu einer schlechten Leistung sowohl auf Trainings- als auch auf Testdaten führt.
Regularisierung / Regularization:
Techniken, die verwendet werden, um Overfitting zu verhindern, indem eine Strafe in die Verlustfunktion aufgenommen wird, die das Modell davon abhält, zu komplex zu werden.
Kreuzvalidierung / Cros-Validation:
Eine Technik zur Bewertung der Modellleistung, indem Daten in mehrere Teilmengen unterteilt und das Modell auf unterschiedlichen Kombinationen dieser Teilmengen trainiert und getestet wird.
Unsicherheitsabschätzungen:
Methoden, die verwendet werden, um die Unsicherheit der Vorhersagen eines Modells zu quantifizieren. Diese sind wichtig für die Bewertung der Vertrauenswürdigkeit von Modellvorhersagen.
ROC-Kurve (Receiver Operating Characteristic):
Eine grafische Darstellung der Vorhersagekraft eines Modells, bei der die Rate der wahren Positiven gegen die Rate der falschen Positiven aufgetragen wird.
AUC (Area Under the Curve):
Die Fläche unter der ROC-Kurve, die als zusammenfassendes Maß für die Modellleistung verwendet wird.
Konfusionsmatrix / Confusion Matrix:
Eine Tabelle, die die tatsächlichen versus die vorhergesagten Klassifikationen eines Modells anzeigt und zur Berechnung von Metriken wie Accuracy, Precision, Recall und F1-Score verwendet wird.
Logarithmische Verlustfunktion / Log-Loss:
Eine Verlustfunktion, die in Klassifikationsproblemen verwendet wird, um die Unsicherheit der Vorhersagen zu messen. Sie wird insbesondere bei Wahrscheinlichkeitsausgaben verwendet.
7. Erklärbarkeit und Transparenz
Green AI (Grüne KI) / Green AI:
Ein Ansatz, der darauf abzielt, die Umweltbelastung durch KI-Entwicklung und -Einsatz zu minimieren. Dazu werden ressourceneffiziente Modelle und Algorithmen verwendet.
Fairness:
Im Kontext der KI bezeichnet ein Vorgehen bei dem darauf geachtet wird, dass KI-Systeme fair arbeiten. Das bedeutet, dsas die Systeme so trainiert werden, dass sie keine Voreingenommenheiten aufweisen und alle Nutzergruppen gerecht behandeltn. Dazu ist es wichtig zu wissen welche Gruppen es theoretisch gibt, um diese in den Trainingsdaten gleichberechtigt repräsentieren zu können.
Erklärbare KI / Explainable AI (XAI):
Der Bereich der KI, der sich mit der Entwicklung von Methoden beschäftigt, um die Entscheidungsfindung von KI-Systemen transparent und verständlich für Menschen zu machen. Dabei wird entgegen dem Black Box Prinzip versucht, KI-Systeme zu entwickeln, deren Entscheidungen transparent für den Nutzer sind, um so das Vertrauen, aber auch die Kontrolle zu erhöhen.
SHAP (SHapley Additive exPlanations):
Ein Verfahren zur Erklärbarkeit von Modellen, das auf den Shapley-Werten aus der Spieltheorie basiert und die Bedeutung jeder Eingabevariable für eine Vorhersage quantifiziert. Es wird also darstellbar gemacht, welche der Eingabedaten eine wie große Rolle für die Entscheidungsfindung spielen.
EU AI Act:
Ist eine Verordnung der Europäischen Union, die Regelungen für die Entwicklung, Bereitstellung und Nutzung von Künstlicher Intelligenz (KI) festlegt. Die Verordnung zielt darauf ab, das Vertrauen in KI-Systeme zu stärken, indem sie Sicherheits-, Transparenz- und Ethikanforderungen definiert.
Adversariale Angriffe / Adversarial Attacks:
Techniken, die darauf abzielen, maschinelle Lernmodelle durch speziell gestaltete Eingaben zu täuschen oder zu manipulieren, um fehlerhafte Vorhersagen zu erzeugen. Beispielsweise sind manche Bildklassifiaktionen anfällig dafür wenn einzelne Pixel verändert werden. Das ist für den Mensch nicht wahrnehmbar kann aber das Modell stark beeinflussen.
Voreingenommenheit / Bias:
Ein systematischer Fehler in den Vorhersagen eines Modells, der durch Vorurteile in den Trainingsdaten oder im Modell selbst verursacht wird und zu ungerechten oder diskriminierenden Ergebnissen führen kann. Mit Vorurteil sind dabei Strukturen in den Daten gemeint, die dazu führen, dass systematisch eine bestimmte Gruppe diskriminiert wird, weil sie z.B. unterrepräsentiert ist.
Robustheit / Robustness:
Die Fähigkeit eines Modells, stabile und verlässliche Vorhersagen zu treffen, auch wenn es mit unerwarteten oder verrauschten Daten konfrontiert wird.
8. Anwendungsgebiete
Gesichtserkennung / Facial Recognition:
Ein Bereich der Bildverarbeitung und Computer Vision, der es Systemen ermöglicht, Gesichter in Bildern oder Videos zu erkennen und zu identifizieren.
Sprachverarbeitung / Speech Processing:
Die Anwendung von KI-Techniken auf Sprachdaten, um Aufgaben wie Sprachtranskription, Spracherkennung und Sprachsynthese durchzuführen.
Empfehlungssysteme / Recommendation Systems:
Systeme, die personalisierte Empfehlungen basierend auf dem Verhalten und den Vorlieben der Nutzer bereitstellen, z. B. in Online-Shops oder Streaming-Diensten.
Objekterkennung:
Ein Computer-Vision-Aufgabenfeld, bei dem ein Modell darauf trainiert wird, spezifische Objekte in Bildern zu identifizieren und zu lokalisieren.
Bildsegmentierung:
Ein Prozess in der Bildverarbeitung, bei dem ein Bild in seine konstituierenden Teile oder Regionen unterteilt wird, oft um Objekte oder Strukturen im Bild zu identifizieren.
Eine Produktionsanlage am Ende der Welt, die Experten des Herstellers hier in Deutschland: Für einen mittelständischen Maschinenbauer war das lange Realität – und ein Riesenproblem, wenn eine Störung auftrat: Bis ein Techniker vor Ort war, um eine Diagnose zu stellen, vergingen oft Tage. Dabei verursacht jede Stunde Stillstand bei teuren und wichtigen Maschinen enorme Schäden für deren Nutzer. Dank eines Digitalisierungsprojekts mit unüberwachtem Lernen gehört dieses Problem der Vergangenheit an.
In einem Forschungsprojekt entwickelte das Forschungszentrum Informatik FZI, einer der Partner des Mittelstand-Digital Zentrums Klima.Neutral.Digital einen KI-basierten Fernwartungsservice, der drohende Ausfälle frühzeitig erkennt – und zwar auf Basis der Sensordaten, die die Anlage ohnehin erfasst. Die Herausforderung: Gerade in kritischen Phasen wie dem Anfahren und Abschalten der Maschinen, etwa für Materialwechsel oder geplante Wartungen, schwanken die Messwerte stark. Im konkreten Fall ging es um große Holzpress-Anlagen.
Kooperation verschiedener Firmen und Klima.Neutral.Digital-Fachleute
Die Firma Dieffenbacher, ein führender Hersteller von Produktionsanlagen für die Holzwerkstoffindustrie, beschäftigte sich intensiv mit der Frage, wie digitale Services die Instandhaltung effektiver und effizienter gestalten können. In Zusammenarbeit mit dem FZI, der SEEBURGER AG und Actimage GmbH entwickelte das Unternehmen einen Demonstrator für das Hydrauliksystem einer Presse.
Methode ermöglicht neue Services und digitale Produkte
Für das menschliche Auge ist kaum zu erkennen, ob alles normal läuft oder sich ein Problem anbahnt. „Mit Verfahren des unüberwachten Lernens brachten wir der KI bei, Anomalien zuverlässig von Normalzuständen zu unterscheiden“, berichtet Janek Bender, Wirtschaftsinformatiker am FZI. Und das, obwohl kaum Trainingsdaten von tatsächlichen Störungen vorlagen. Denn diese treten höchst selten auf. Wenn aber doch, verursachen sie enorme finanzielle Schäden. Das frühzeitige Erkennen ermöglicht es nun, rechtzeitig Gegenmaßnahmen einzuleiten und Ausfälle zu vermeiden. In dem die Fachleute für Datenanalyse und Services eng zusammenarbeiteten, entstanden KI-Modelle zur Anomalieerkennung, die sich in spezifische Smart Services integrieren ließen. Somit kann das Unternehmen gezielte Überwachungsfunktionen mit aggregierten Kennzahlen sowie Inspektions- und Instandsetzungsprozesse anbieten und die Kunden bei der Analyse der Fehlerursachen oder -behebung Schritt für Schritt unterstützen. Die Erfahrungen fließen nun in den weiteren Ausbau von Online-Services und neuen digitalen Produkten ein.
Verbesserte vorausschauende Instandhaltung
Anomalien zu erkennen, sei ein Paradebeispiel für die Stärken der KI, sagt Bender. Vorausschauende Instandhaltung (Predictive Maintenance Condition Monitoring) lässt sich damit entscheidend verbessern. Nicht nur bei Holzpressen, sondern überall, wo eine Fernüberwachung von Anlagen stattfindet. Kleine und mittelständische Unternehmen (KMU) können davon enorm profitieren. Dabei unterstützt das Team von Klima.Neutral.Digital. Gemeinsam mit dem Unternehmen erarbeiten die KI-Trainer, wie sich Anomalieerkennung in Anlagen implementieren lässt.
Wie lässt sich die Produktion von Insekten effizienter und nachhaltiger gestalten? Dieser Frage geht ein Digitalisierungsprojekt des Mittelstand-Digital Zentrums Klima.Neutral.Digital nach. Gemeinsam mit einem jungen Unternehmen entwickelt ein Team einen digitalen Zwilling, der Wachstum und Futter der Insektenpopulation optimiert.
Kern des „Insektenzwillings“ sind KI-Modelle, die Menge und Gewicht von Mehlwurm-Larven auf Basis von Bilddaten schätzen. Diese Informationen fließen zusammen mit Sensordaten zu Temperatur, Feuchtigkeit und anderen Parametern in eine virtuelle Abbildung der Zuchtanlage. Anhand dieser Simulation lässt sich ermitteln, wie sich unterschiedliche Futtermischungen und Umgebungsbedingungen auf Wachstum und Gesundheit der Tiere auswirken. „Wir wollen die Rezeptur so optimieren, dass sie möglichst wenige Ressourcen verbraucht, aber die Insekten optimal gedeihen“, erklärt Janek Bender vom Klima.Neutral.Digital-Partner Forschungszentrum Informatik FZI. Gerade in Zeiten knapper und schwankender Rohstoffe sei das ein wichtiger Hebel für mehr Produktivität und Kreislaufwirtschaft. Denn als Futter kommen vor allem Reststoffe zum Einsatz, deren Zusammensetzung stark variiert. Mit KI-Unterstützung passt sich die Rezeptur dynamisch daran an.
Von Insekten bis Gebäudetechnik: Universell einsetzbar
Prozesse durch „Smart Twins“ zu optimieren, hat Potenzial weit über die Insektenzucht hinaus. Ein Bereich, in dem dies bereits vor Jahren erkannt wurde, ist das Bau- und Immobilienwesen mit dem Building Information Modelling (BIM). Mit dem Einsatz von Bilderkennungs-KI ist es denkbar, diese BIM-Datensätze der verbauten Gebäudetechnik allein über Fotos der Immobilie zu erstellen.
Technik spielt ihre Vorteile in komplexen Systemen aus
„Überall, wo komplexe Systeme von schwer kontrollierbaren Größen abhängen, kann dieser Ansatz helfen, bessere Ergebnisse zu erzielen“, erklärt Bender. Weitere Einsatzfelder sieht er etwa in der Lebensmittel- und Pharmaindustrie oder der Energiewirtschaft. Der Wirtschaftsinformatiker ermutigt daher kleine und mittlere Unternehmen, gemeinsam mit Klima.Neutral.Digital die Möglichkeiten der Technologie auszuloten.
In der Regel sei der erste Schritt, digitale Zwillinge von Maschinen zu erstellen. Dieser kann beispielsweise als Datenquelle dafür dienen, um mittels eines KI-Tools vorausschauende Instandhaltung zu betreiben, die Maschinensteuerung optimieren, Simulationen fahren oder Prognosen erstellen. In einem konkreten Projekt mit einem Mittelständler konnten so die Soll- und Liegezeiten in der Produktion um bis zu 50 Prozent reduziert werden. Des Weiteren kann man mit KI-Tools in digitalen Zwillingen Produktion energieflexibel planen, um Stromkosten zu reduzieren, wie der Klima.Neutral.Digital-Demonstrator Eflex zeigt – in diesem Fall mit der Methode des Reinforcement Learning.
Mittelstand-Digital unterstützt kleine und mittlere Unternehmen
Der erste Schritt zum Digitalen Zwilling kann ein Strategiegespräch mit Fachleuten von Klima.Neutral.Digital sein. Hier gilt es zunächst, die individuellen Ziele und Rahmenbedingungen des Unternehmens zu verstehen. Darauf aufbauend entwickelt das Team ein maßgeschneidertes Konzept, wie sich digitale Zwillinge gewinnbringend einsetzen lassen. So hilft es dabei, Mittelständlern den Zugang zu einer Schlüsseltechnologie der Zukunft zu ermöglichen.
Bisher war es Sache von Spezialisten, KI-Modelle zu entwickeln. Doch mit AutoML – Automated Machine Learning – ändert sich das. Ein Ziel des Mittelstand-Digital Zentrums Klima.Neutral.Digital ist es, dass auch Domänenexperten ohne tiefes KI-Know-how KI-Modelle für ihre Aufgaben erstellen können.
Möglich macht das eine weitgehende Automatisierung des Entwicklungsprozesses. Die AutoML-Software wählt geeignete Algorithmen aus, optimiert Parameter und trainiert die Modelle. „Im Idealfall definiert man nur noch Daten und Ziel und erhält ein fertiges Modell“, erklärt Janek Bender vom Klima.Neutral.Digital-Partner FZI Forschungszentrum Informatik. So können Fachleute wie Fertigungsingenieure, Prozessplaner oder Leute in der Qualitätssicherung befähigt werden, mit einem AutoML-Werkzeug leichtgewichtig und schnell selbst KI-Modelle aufzusetzen.
Selbst erstelltes KI-Modell optimiert die Produktionsplanung
In einem konkreten Anwendungsfall ging es darum, für ein mittelständisches Unternehmen aus der Fertigungsindustrie die Durchlaufzeiten seiner Produktion zu optimieren. Bisher verlief die Planung oft ungenau, weil die vielen verschiedenen Einflussfaktoren menschlich kaum zu überblicken waren. Mithilfe von AutoML entwickelten die Fachleute innerhalb weniger Tage ein Prognosemodell, das auf Basis bisheriger Auftragsdaten präzise Vorhersagen für die Dauer einzelner Prozessschritte trifft. Dieses Werkzeug liefert nun wertvolle Entscheidungsgrundlagen, um die Produktion zu planen und ermöglicht es, Ressourcen effizienter zu steuern.
Mittelstand-Digital Zentrum stellt Programme und Trainer bereit
Um die Vorteile von AutoML interaktiv zu vermitteln und Unternehmen bei der Entwicklung eigener Use-Cases zu unterstützen, hat Klima.Neutral.Digital den Demonstrator AutoML MDZ Tool entwickelt. Er steht kostenlos zur Verfügung und wurde speziell für Mittelständler konzipiert.
AutoML automatisiert viele zeitaufwändige Schritte, die bei der manuellen Anwendung von maschinellem Lernen anfallen und spezifische KI-Expertise erfordern. Dazu zählen die Auswahl geeigneter KI-Modelle und die Optimierung von Hyperparametern. Durch vordefinierte Regeln und Optimierungsalgorithmen nimmt AutoML nicht nur KI-Fachkräften Arbeit ab, sondern ermöglicht es auch Unternehmen mit wenig KI-Erfahrung, vollwertige KI-Applikationen zu erstellen – ganz ohne Programmierung. Aktuell arbeitet der Klima.Neutral.Digital-Partner Zentrum für Sonnenenergie- und Wasserstoff-Forschung Baden-Württemberg daran, das Tool zu implementieren und bereitzustellen. Eine vorläufige Demo-Version ist bereits verfügbar. Des Weiteren hat das ZSW die No-Code AutoML KI-Lab.EE entwickelt, mit der man sich ein KI-Modell erstellen kann. Innerhalb von Klima.Neutral.Digital stehen die KI-Trainer und Digtialisierungsfachleute bereit, Unternehmen dabei zu unterstützen. Beispielsweise, wenn bereits Daten vorliegen. Diese verarbeitet man manuell vor, um anschließend mittels AutoML ein einfaches KI-Modell zu entwickeln, erklärt Bender.
Wettbewerbsvorteil für den Mittelstand
Gerade für den Mittelstand sieht der Experte großes Potenzial: „Mit AutoML sammeln Unternehmen schnell und kostengünstig erste Erfahrungen mit KI und setzen eigene Ideen um.“ So sichern sie sich Wettbewerbsvorteile, ohne ein Team von Data Scientists aufbauen zu müssen. Denn KI-Experten sind rar und teuer – Domänenwissen dagegen ist in jedem Unternehmen vorhanden. Und mit der richtigen Unterstützung durch Klima.Neutra.Digital lässt sich daraus KI-Gold schürfen.
Auch Interessant



Erneuerbare Energien sind wetterabhängig. Wer auf der Verbraucherseite flexibel ist, kann diese Schwankungen in der Stromerzeugung zum eigenen Vorteil nutzen. Lastmanagement ist hier das Stichwort: Durch gezielte Steuerung von Verbrauchern können kleine und mittlere Unternehmen (KMU) Kosten reduzieren oder sogar Einnahmen generieren.
Inhaltsverzeichnis
Ein Paradebeispiel ist, den Eigenverbrauch von Photovoltaik-Strom zu maximieren. Wann immer die eigene PV-Anlage Überschüsse produziert, sollte man schauen, ob sich Lasten in diese Zeiten verschieben lassen, empfiehlt Tobias Riedel, stellvertretender Abteilungsleiter im Bereich Intelligent Systems and Production Engineering beim Klima.Neutral.Digital-Partner Forschungszentrum Informatik in Karlsruhe. Das können Elektroautos von Mitarbeitenden sein, die auf dem Firmenparkplatz laden. Statt alle Fahrzeuge morgens mit Strom aus dem Netz voll zu laden und den Solarstrom mittags für eine geringe Vergütung einzuspeisen, verteilt man die Ladevorgänge intelligent über den Tag. Auch Wärmepumpen und Speicher eignen sich hervorragend für ein solches Lastmanagement.
Kosten reduzieren durch netzorientierte Steuerung
Ein weiterer Anwendungsfall ist die netzorientierte Steuerung nach Paragraf 14a des Energiewirtschaftsgesetzes. Dabei gestattet man dem Netzbetreiber, im Notfall die Leistung von steuerbaren Verbrauchern wie Ladestationen, Wärmepumpen oder Speichern zu reduzieren, um das Netz stabil zu halten. Dies bekommt man mit einer pauschalen Netzentgeltreduktion von 60 Prozent oder einem Pauschalbetrag vergütet. Pro Jahr sind so 150 bis 200 Euro Ersparnis drin, so Riedel. Und zwar, ohne dass man Komforteinbußen hat, da die Netzbetreiber bislang nicht aktiv steuern.
Auch dynamische Stromtarife, die sich an der Börse orientieren, werden in Zukunft eine größere Rolle spielen. Dafür benötigt man einen Smart-Meter. Durch geschicktes Steuern der Ladevorgänge und anderer flexibilisierbarer Verbrauche, können KMU Kosten einsparen. Das gilt besonders für Unternehmen, die keine eigene PV-Anlage betreiben oder Verbraucher, die von Solarstrom wenig profitieren, wie Wärmepumpen, die vor allem im Winter laufen.
Wer Regelenergie anbietet, kann damit Geld verdienen
Wer es einen Schritt weiter gehen will, kann sogar als Anbieter von Regelenergie auftreten und damit Geld verdienen, beschreibt Riedel. Dazu müssen Anlagen wie Blockheizkraftwerke, Kühlhäuser oder Ladesäulen ihre Leistung für einen gewissen Zeitraum hoch- oder herunterfahren können. „Das geht allerdings nicht in Eigenregie, sondern nur über spezielle Dienstleister, sogenannte Aggregatoren. Diese bündeln viele kleine Anlagen, bis sie am Regelenergiemarkt die erforderliche Mindestleistung von einem Megawatt erreichen.“ Über eine Steuerbox des Aggregators lässt sich die Anlage dann innerhalb der vereinbarten Grenzen fernsteuern. Bisher sind in diesem Geschäft vor allem Kraftwerke aktiv – doch auch mit Demand-Side-Management lässt sich Regelleistung bereitstellen, betont der Experte.
Potenziale zur Flexibilisierung schlummern in praktisch jedem Unternehmen
Generell gilt: „Wer sich vorstellen kann, Verbrauchsanlagen zu flexibilisieren, sollte das Thema Lastmanagement auf dem Schirm haben“, sagt Riedel. Sei es, um den Strombezug zu optimieren oder um neue Erlösquellen zu erschließen. Auch die Strombeschaffung sollte man betrachten. Wer dauerhaft einen hohen, unflexiblen Strombedarf hat, sollte vor allem schauen, wie er diesen möglichst günstig und nachhaltig decken kann.
Gute Ansatzpunkte für Lastmanagement finden sich in praktisch jedem Unternehmen: Ob Heizung, Lüftung, Klimatisierung, Ladeinfrastruktur oder Speicher – fast überall schlummern Potenziale. Selbst Notstromaggregate lassen sich netzdienlich einsetzen, indem man ohnehin nötige Testläufe in Zeiten verlegt, in denen das Stromnetz gerade Bedarf hat – und sich dies vergüten lässt. Das Team von Klima.Neutral.Digital unterstützt kleinere und mittlere Unternehmen dabei, diese Potenziale zu finden und zu nutzen. Nehmen Sie jetzt Kontakt auf!
Ob etabliertes Unternehmen oder innovatives Startup – wer heute neue Geschäftsmodelle entwickelt, kommt am Thema Nachhaltigkeit nicht vorbei. Doch wie lassen sich digitale Angebote von Anfang an klimafreundlich gestalten? Und wie schafft man bei bestehenden Geschäftsmodellen den Wandel in Richtung Klimaneutralität? Dr. Marcus Winkler, Digitalisierungsexperte beim Mittelstand-Digital Zentrum Klima.Neutral.Digital, kennt die Antworten. Denn er hat einen Demonstrator für klimaneutrale, digitale Geschäftsmodelle entwickelt.
„Es gibt viele Hebel, um ein Geschäftsmodell klimafreundlicher zu machen“, sagt Winkler. Ein wichtiger Ansatzpunkt ist die Gestaltung der Produkte und Dienstleistungen selbst. Langlebigkeit spielt hier eine zentrale Rolle. Auch der Einsatz nachhaltiger Materialien oder ressourcenschonender Herstellungsverfahren mit geringerem Wasser- und Stromverbrauch hat Potenzial. Gleichzeitig bergen heute digitale Geschäftsmodelle die besten Chancen auf Wachstum.
Analyse auf Basis bewährter Modelle
Bei Klima.Neutral.Digital setzt man auf einen strukturierten Prozess, um Unternehmen dabei zu unterstützen, klimaneutrale und digitale Geschäftsmodelle zu entwickeln. Dazu hat Winkler einen Demonstrator entwickelt. Dieser basiert auf bewährten Methoden wie dem Business Model Canvas und dem Business Model Navigator. In Workshops erarbeiten die Teilnehmer damit Ideen, wie sich ihr Geschäftsmodell Schritt für Schritt klimaneutral umbauen lässt.
Sieben Schritte zur neuen Strategie
Zunächst werden die grundlegenden Bausteine eines Geschäftsmodells wie Wertversprechen (Value Proposition) und Kundensegmentierung (Customer Segment) erarbeitet. Darauf aufbauend unterstützt das Klima.Neutral.Digital-Team kleine und mittlere Unternehmen (KMU) in sieben Schritten dabei, ihr individuelles digitales und klimaneutrales Geschäftsmodell zu entwickeln. „Wir schauen uns gemeinsam an, welche Maßnahmen den größten Impact versprechen“, sagt Winkler. Dabei gilt es, Besonderheiten der eigenen Branche und des Marktes zu berücksichtigen. Produktspezifika, gesetzliche Vorgaben oder die Charakteristika zweiseitiger Märkte müssen von Anfang an mitgedacht werden. Auch digitale und nicht-digitale Elemente gilt es sinnvoll zu kombinieren, um Synergien zu heben.
Klimaschutz als Wettbewerbsvorteil
Ziel ist nicht nur, den eigenen CO2-Fußabdruck zu verkleinern. „Ein klimaneutrales Geschäftsmodell bietet auch große Chancen am Markt“, ist sich der Experte sicher. Noch zögern viele KMU, ihre Geschäftsmodelle weiterzuentwickeln, insbesondere dann, wenn diese noch funktionieren. Aber immer mehr Kunden achteten auf Nachhaltigkeit und seien bereit, für entsprechende Angebote auch mehr zu bezahlen. „Wer sich hier frühzeitig positioniert, kann sich einen echten Wettbewerbsvorteil verschaffen“, sagt Winkler.
Banken und Regulierer verlangen CO2-Reduzierung
Gerade für KMU ist es wichtig, sich mit Nachhaltigkeit und Digitalität auseinanderzusetzen. „Die Märkte ändern sich rasant und der Druck in Richtung Klimaneutralität wird weiter zunehmen“, mahnt Winkler. Dies gelte nicht nur für die Kundenseite, sondern auch für Investoren und Regulierer. Unternehmen, die schon heute konsequent auf Nachhaltigkeit setzen, sichern so ihre Zukunftsfähigkeit. Dabei unterstützt Klima.Neutral.Digital – mit kostenfreien Workshops, Analysen und einem erprobten Vorgehen.
Auch Interessant



Wie viel CO2 verursacht ein Produkt meines Unternehmens pro Stück? An welchen Stellschrauben kann ich drehen, um die Emissionen zu reduzieren? Diese Fragen beschäftigen immer mehr Firmen. Die Antworten zu finden, ist oft nicht leicht. Doch dabei hilft der MFCA-Demonstrator des Mittelstand-Digital Zentrums Klima.Neutral.Digital.
Entwickelt und parametrisiert hat das Tool Jürgen Seibold, Spezialist für intelligente, nachhaltige Produktion beim Klima.Neutral.Digital-Unterauftragnehmer Deutsche Institute für Textil- und Faserforschung (DITF). Mit dem Demonstrator zur Nachhaltigkeitsmodellierung und -bewertung können produzierende Unternehmen schnell und einfach den Carbon Footprint von Produkten (PCF) ermitteln. Dieser basiert auf der Methode des Material Flow Cost Accounting (MFCA), die man üblicherweise verwendet, um die Kosten von Produkten zu berechnen. Programmiert hat Seibold den Demonstrator in einem Standard-Programm für Lebenszyklus-Analysen. „Wir nutzen dafür die Software Umberto LCA+, mit der sich Produktionsprozesse modellieren und analysieren lassen“, erklärt er.
Software macht die Auswirkungen einzelner Prozessschritte sichtbar
Will man den CO2-Abdruck ermitteln, werden zunächst alle relevanten Prozessschritte erfasst – vom Materialeingang über die einzelnen Bearbeitungsstufen bis hin zur Auslieferung. Für jeden Schritt trägt man die benötigten Einsatzfaktoren wie Rohstoffe, Energie oder Betriebsmittel ein. Die Software greift dann auf hinterlegte Datenbanken zu und berechnet die damit verbundenen Emissionen für jeden Schritt der Verarbeitungskette. Dies stellt sie in einem Prozess-Schaubild dar und macht so große Auswirkungen auf einen Blick sichtbar. „So erhält man sehr schnell einen Überblick, welche Prozesse besonders CO2-intensiv sind und wo die größten Hebel für Einsparungen liegen“, erklärt Seibold.
Oft ergäben sich dabei Aha-Effekte, welcher Schritt als besonders CO2-intensiv heraussteche. An diesem setze man dann zuerst an, um den Fußabdruck zu minimieren. Zum Beispiel, indem man eine erste Qualitätssicherung in der Kette nach vorne verlagert, bevor die Produkte in einen energieintensiven Verarbeitungsprozess gehen.
Simulation berechnet Einsparpotenziale
Um Einsparpotenziale aufzudecken, lassen sich in dem Modell ganz einfach Änderungen simulieren: Wie wirkt es sich aus, wenn ich Materialien austausche, Prozesse verändere oder auf Ökostrom umstelle? Welche Maßnahmen bringen den größten Effekt? „Unser Ziel ist es, dass die Unternehmen eine Entscheidungsgrundlage bekommen, um die richtigen Stellschrauben in Richtung CO2-Reduktion zu drehen“, so Seibold. Da er mit demselben Demonstrator auch die Stückkosten berechnen und mit den eigenen Kalkulationen der Unternehmen vergleichen kann, erhält man sofort eine Abschätzung, wie valide die Daten des Modells sind, also wie nah an den tatsächlichen Prozesskosten bzw. dem Carbon Footprint.
Schnelle CO2-Berechnung für den Mittelstand
Oft haben gerade kleine und mittlere Unternehmen (KMU) nicht die Kapazitäten, um sich tiefgehend mit dem Thema Ökobilanzierung zu beschäftigen. Doch auch diese sind als Zulieferer zunehmend gefordert, den CO2-Fußabdruck ihres Produkts zu benennen oder Berichtspflichten zu erfüllen. „Mit unserem Demonstrator können auch KMU ganz niedrigschwellig einsteigen und wertvolle Erkenntnisse für mehr Klimaschutz im eigenen Betrieb gewinnen“, betont der Experte. Wie alle Unterstützungsangebote von Klima.Neutral.Digital ist dieses Angebot für Mittelständler kostenfrei.
Klassische KI-Modelle lernen einmal mit einem festen Datensatz und arbeiten dann unverändert – bis die Realität sich so weit gewandelt hat, dass ihre Vorhersagen ungenau werden. Beim Lifelong Learning hingegen wird die Künstliche Intelligenz mit neuen Daten permanent weitertrainiert und damit -verbessert.
„Wir entwickeln KI-Systeme, die kontinuierlich aus Datenströmen lernen“, erklärt Janek Bender, Wirtschaftsinformatiker beim FZI Forschungszentrum Informatik, einer der Partner des Mittelstand-Digital Zentrum Klima.Neutral.Digital. „So passen sie sich an Veränderungen an und treffen weiter zuverlässige Vorhersagen.“ Eine solche Lifelong Learning KI – oder auch Online Learning im Gegensatz um Offline Learning mit einem statischen Datensatz – kann gerade im dynamischen Umfeld produzierender kleiner und mittlerer Unternehmen (KMU) von Vorteil sein, wenn sich Prozesse, Materialien und Bedingungen ständig wandeln.
Kosten gesenkt – Termine besser planbar
In einem Projekt mit mehreren Unternehmen zeigte Bender, wie Lifelong Learning KI die Soll- und Liegezeiten in der Produktion um bis zu 50 Prozent genauer prognostiziert als gängige Methoden, also die Zeit für einen Prozessschritt in der Produktion und die Zeit, in der das Teil dazwischen lagert. Durch die präzisere Planung der Produktionsabläufe sinken die Kosten. Liefertermine lassen sich besser einhalten.
Einsetzbar für alle Arten von veränderlichen Datenströmen
Doch Lifelong Learning eignet sich nicht nur für Zeitreihen aus der Fertigung. Auch Sensordaten von Maschinen und Anlagen, Energieverbräuche oder Absatzzahlen lassen sich damit analysieren und Vorhersagemodelle kontinuierlich verbessern. „Überall, wo Datenströme anfallen, lässt sich dieser Ansatz im Prinzip anwenden“, betont Bender. Und hilft Mittelständlern dabei, das Potenzial ihrer Daten voll auszuschöpfen, besonders dann, wenn diese Daten sich recht häufig verändern. Concept-Drift-Detektoren können diese Veränderungen aufspüren. „Über Concept Drift Adaption kann man das Modell so anpassen, dass es auf den neuen Daten funktioniert“, so Bender. Denn das Ziel ist eine möglichst robuste KI.
KI-Trainer stehen zur Unterstützung bereit
Interessierte Unternehmen können sich an die KI-Trainer von Klima.Neutral.Digital wenden, um die Möglichkeiten von Lifelong Learning für ihre spezifischen Anwendungsfälle zu diskutieren. In einem Erstgespräch analysieren diese gemeinsam mit den Firmenvertretern die Ausgangssituation und skizzieren mögliche Lösungsansätze. So lässt sich schnell herausfinden, ob und wie das Unternehmen von der Technologie profitieren kann.
Wer Energieflüsse clever steuern will, muss wissen, was wann in welchem Umfang verbraucht wird und wann wie viel Strom zu welchen Preisen verfügbar sein wird. Prognosen sind hier ein zentrales Hilfsmittel. Sie ermöglichen es, den Energieeinsatz zu planen und zu optimieren.
Inhaltsverzeichnis
Zum einen geht es für kleine und mittlere Unternehmen darum, den eigenen Verbrauch vorherzusagen: Wie viel Strom wird in den nächsten Stunden oder Tagen benötigt? Welche Anlagen laufen wann? Welche Lasten sind beeinflussbar, welche nicht? Nur so lässt sich ermitteln, wie viel Flexibilität zur Verfügung steht. Diese ist Voraussetzung für ein intelligentes Energiemanagement. Auch die Wärme- und Kältebedarfe spielen hier mit hinein.
Andererseits sind auch Prognosen wichtig, wann Strom besonders günstig sein wird – anhand von Wettervorhersagen und Daten des Strommarkts. Denn die Strompreise an der Börse stehen am Vortag fest. Falls vorhanden, muss man zusätzlich die Erzeugung des eigenen PV-Stroms prognostizieren, um den Eigenverbrauch zu optimieren. Einige Dienstleister bieten hier bereits Services an, die anhand von Wetterdaten und Anlagenparametern die Produktion in den nächsten Stunden und Tagen vorhersagen. Über Lastmanagement lassen sich dann Verbrauch optimieren und Kosten reduzieren.
Algorithmen prognostizieren Verbrauch und lernen selbst dazu
Gerade Gebäude bieten durch ihre thermische Trägheit oft Spielräume für eine flexible Betriebsweise von Heizung und Kühlung. Hier kommt es darauf an, das Gebäudeverhalten richtig vorherzusagen: Wie entwickeln sich Temperatur und Energiebedarf, wenn ich die Heizung für eine gewisse Zeit etwas herunterregele oder die Kühlung später einschalte? Welche Abweichungen vom Sollwert sind akzeptabel, ohne dass es zu Komforteinbußen kommt? Ein halbes Grad Unterschied in der Raumtemperatur wird nicht wahrgenommen, kann aber bereits helfen, Energie einzusparen. Früher musste man für solche Vorhersagen mühsam Daten zusammentragen und Modelle erstellen. Heute übernehmen das zunehmend intelligente Algorithmen. So lässt sich der Energieverbrauch von Gebäuden oder Anlagen vorhersagen, ohne dass man jedes Detail manuell erfassen und modellieren muss.
Je mehr Daten, desto treffsicherer die Vorhersagen
Die Expertinnen und Experten von Klima.Neutral.Digital arbeiten auch mit Methoden des maschinellen Lernens, wenn sie kleine und mittlere Unternehmen unterstützen. Die Algorithmen analysieren Verbrauchsdaten der Vergangenheit, erkennen Muster und bilden so das Systemverhalten nach. Dabei lernen sie selbstständig, welche Einflussfaktoren relevant sind – von Wetter und Belegung bis hin zu Ferienzeiten. Je mehr Daten zur Verfügung stehen, desto treffsicherer werden die Modelle.
Auf Basis solcher Prognosen lassen sich Fahrpläne für eine optimierte Energienutzung erstellen. Weichen die tatsächlichen Verbräuche von der Vorhersage ab, passen lernende Algorithmen die Planung laufend an. So wird das System im Laufe der Zeit immer genauer und treffsicherer.
Dabei muss es gar nicht immer um einzelne Anlagen oder Gebäude gehen. Auch für einen ganzen Unternehmensstandort lässt sich anhand historischer Lastgänge ein Verbrauchsprofil erstellen und fortschreiben. So erkennt man typische Muster wie Tages- und Wochenzyklen und kann die Beschaffung und Erzeugung von Energie vorausschauend planen.