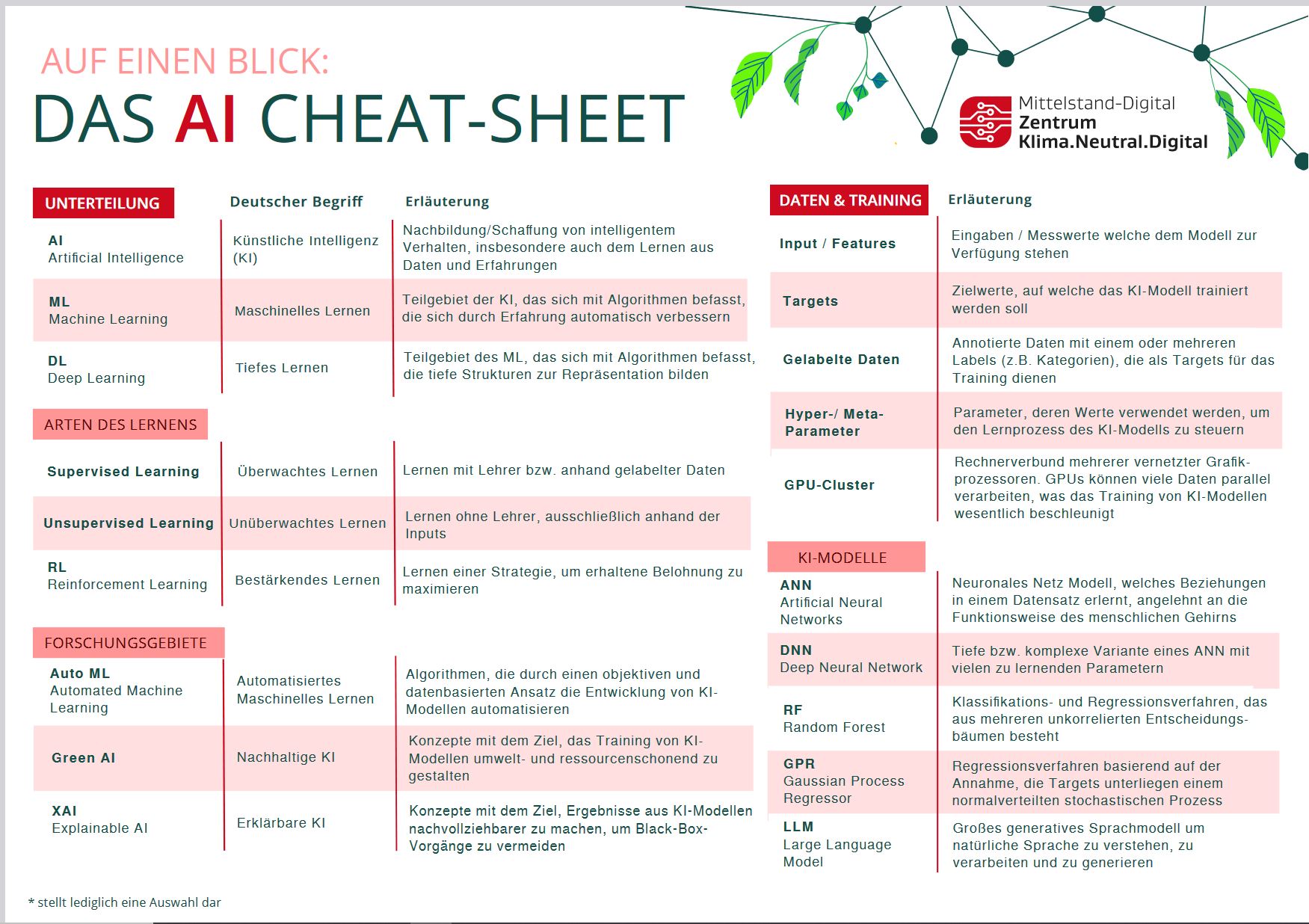
Begriffsübersicht Künstliche Intelligenz

Technologien wie Künstliche Intelligenz bringen viele Fachbegriffe und Ausdrucksweisen mit sich, die für Nicht-Profis eine Hürde darstellen können. Um sich einem komplexen Thema zu nähern, ist ein Verständnis der Begrifflichkeiten unabdingbar. Im Nachfolgenden finden Sie daher eine ausführliche Auflistung der gängigsten Begriffe mit kurzen leicht verständlichen Erklärungen von unseren KI-Trainer:innen.
Tipp: Suchen Sie ein bestimmtes Wort, geben Sie es in die Suchfunktion Ihres Browsers ein.
Vermissen Sie einen Begriff? Schreiben Sie uns!
Inhaltsverzeichnis
1. Grundbegriffe
Künstliche Intelligenz (KI) / Artificial Intelligence (AI):
Das breite Feld, das sich mit der Entwicklung von Maschinen beschäftigt, die Aufgaben ausführen können, die normalerweise menschliche Intelligenz erfordern, wie z.B. das Erkennen, Lernen und Problemlösen.
Maschinelles Lernen / Machine Learning (ML):
Ein Teilbereich der KI, der sich auf die Entwicklung von Algorithmen konzentriert, die es Computern ermöglichen, aus Daten zu lernen und Vorhersagen zu treffen.
Deep Learning:
Ein Teilbereich des maschinellen Lernens, der neuronale Netzwerke mit vielen Schichten (daher „tief“) verwendet, um komplexe Muster in großen Datensätzen zu modellieren.
Generative KI / Generative AI:
Eine Art von KI, die in der Lage ist, neue Inhalte (Text, Bilder, Musik) basierend auf den Daten zu erstellen, auf denen sie trainiert wurde, wie z.B. GPT für Text oder DALL-E für Bilder.
Verarbeitung natürlicher Sprache / Natural Language Processing (NLP):
Ein Bereich der KI, der sich auf die Interaktion zwischen Computern und Menschen durch natürliche Sprache konzentriert und Aufgaben wie Übersetzung, Sentimentanalyse und Texterstellung ermöglicht.
Bildverarbeitung / Computer Vision:
Ein Bereich der KI, der darauf abzielt, Maschinen zu befähigen, visuelle Informationen aus der realen Welt zu interpretieren und zu verstehen, wie z. B. das Erkennen und Klassifizieren von Objekten in Bildern.
Klassifikation:
Eine Art von überwachten Lernproblems, bei dem das Ziel darin besteht, Eingabedaten in eine von mehreren vordefinierten Kategorien einzuordnen.
Regression:
Ein überwachter Lernansatz, bei dem das Ziel ist, einen kontinuierlichen Wert vorherzusagen, basierend auf Eingabedaten. Beispiel: Vorhersage des Preises eines Hauses.
Black Box:
Ein Begriff, der ein Modell beschreibt, dessen interne Funktionsweise schwer nachvollziehbar ist. Dies trifft oft auf komplexe Modelle wie tiefe neuronale Netzwerke zu.
2. Lernarten
Überwachtes Lernen / Supervised Learning:
Eine Art des maschinellen Lernens, bei dem das Modell auf gelabelten Daten trainiert wird, was bedeutet, dass jedes Trainingsbeispiel mit einer zugehörigen richtigen Antwort versehen ist.
Unüberwachtes Lernen / Unsupervised Learning:
Eine Art des maschinellen Lernens, bei dem das Modell auf Daten ohne explizite Labels trainiert wird. Das Modell versucht selbstständig, Muster oder Strukturen in den Daten zu erkennen. Ein typisches Beispiel ist das Gruppieren von ähnlichen Daten.
Verstärkendes Lernen / Reinforcement Learning:
Ein Lernparadigma, bei dem ein Agent durch Interaktionen mit einer Umgebung lernt. Der Agent erhält basierend seiner ausgeführten Aktionen Belohnungen oder Strafen und lernt so Stück für Stück, seine Strategie entsprechend zu verbessern.
3. Modelle und Algorithmen
Diskriminator:
Ein Modell, das in Generative Adversarial Networks (GANs) verwendet wird, um echte Daten von durch einen Generator erzeugten gefälschten Daten zu unterscheiden.
Generator:
Ein Modell in einem GAN, das darauf trainiert wird, Daten zu erzeugen, die dem realen Datensatz ähneln. Der Generator versucht, den Diskriminator zu täuschen.
Parametrisches Modell:
Ein Modell, das eine feste Anzahl von Parametern hat, die unabhängig von der Menge der Trainingsdaten ist. Beispiele sind lineare Regression oder logistische Regression.
Nicht-Parametrisches Modell:
Ein Modell, das keine feste Anzahl von Parametern hat und seine Komplexität an die Menge der Trainingsdaten anpasst. Beispiele sind K-Nearest Neighbors (K-NN) oder Decision Trees.
Ensemble Methoden:
Techniken, bei denen mehrere Modelle kombiniert werden, um die Leistung zu verbessern. Beispiele sind Random Forests oder Gradient Boosting.
Variational Autoencoder (VAE):
Eine Art von Autoencoder, die probabilistische Modelle verwendet, um Eingabedaten zu rekonstruieren und gleichzeitig latente Variablen zu lernen, um die Datenverteilung zu modellieren.
BERT (Bidirectional Encoder Representations from Transformers):
Ein leistungsstarkes Sprachmodell, das bidirektionale Kontextinformationen verwendet, um präzisere Textdarstellungen für Aufgaben wie Frage-Antwort-Systeme und Textklassifikation zu erzeugen.
Bidirektionale Kontextinformationen:
Ein Konzept, bei dem Informationen aus dem Kontext sowohl in vorwärts- als auch in rückwärtsgerichteten Richtungen verarbeitet werden, um eine umfassendere Darstellung der Daten zu erzeugen. Häufig verwendet in Modellen wie bidirektionalen RNNs oder BERT.
Generative Pre-trained Transformer (GPT):
Ein Sprachmodell, das auf einer großen Textmenge vortrainiert wird, um menschenähnlichen Text zu generieren und für eine Vielzahl von Aufgaben der natürlichen Sprachverarbeitung verwendet wird.
Neuronale Netzwerke / Neural Networks:
Computermodelle, die vom menschlichen Gehirn inspiriert sind und aus Schichten von miteinander verbundenen Knoten (Neuronen) bestehen, die Daten auf komplexe Weise verarbeiten.
Künstliches Neuronales Netzwerk (KNN) / Artificial Neural Network (ANN):
Eine Art neuronales Netzwerk mit einer oder mehreren Schichten. Es ist der grundlegende Baustein des Deep Learning.
Tiefes Neuronales Netzwerk (TNN) / Deep Neural Network (DNN):
Ein KNN mit mehreren verborgenen Schichten zwischen der Eingabe- und Ausgabeschicht. Diese werden verwendet, um komplexe Datenmuster zu modellieren.
Convolutional Neural Network (CNN):
Eine Art tiefes neuronales Netzwerk, das sich besonders gut für die Verarbeitung von gitterartigen Daten wie Bildern eignet. Es verwendet Faltungsschichten, um automatisch Merkmale wie Kanten und Texturen zu erkennen.
Rekurrentes Neuronales Netzwerk / Recurrent Neural Network (RNN):
Ein neuronales Netzwerk, das für die Verarbeitung sequenzieller Daten entwickelt wurde, indem es Informationen über Zeiträume hinweg speichert und verarbeitet, wie z.B. bei der Text- oder Spracherkennung.
Transformer:
Eine moderne Architektur für neuronale Netzwerke, die vor allem in NLP verwendet wird und sich durch die Fähigkeit auszeichnet, parallele Verarbeitung und Selbstaufmerksamkeit (self-attention) zu nutzen, wie z. B. bei Modellen wie GPT und BERT.
Graph Neural Network (GNN):
Ein neuronales Netzwerk, das speziell für die Arbeit mit Graphdaten entwickelt wurde, wie z.B. soziale Netzwerke oder Molekularstrukturen.
Autoencoder:
Eine spezielle Art von neuronalen Netzwerken, die verwendet wird, um effiziente Kodierungen von Daten zu lernen, oft für Aufgaben wie Dimensionenreduktion oder Anomalieerkennung.
Generatives Adversariales Netzwerk / Generative Adversarial Network (GAN):
Ein Paar von neuronalen Netzwerken, die gegeneinander antreten: ein Generator, der versucht, realistische Daten zu erstellen, und ein Diskriminator, der versucht, echte von generierten Daten zu unterscheiden.
Retrieval-Augmented Generation (RAG):
Eine Technik, die generative Modelle systematisch mit Kontextinformationen aus einer oder mehreren Datenbanken anreichert, um präzisere und informativere Antworten zu generieren. Dabei wird die ursprüngliche Eingabe durch besonders passende Kontextinformationen angereichert, bevor die Antwort durch das LLM generiert wird.
Gaussian Process Regression (GRP):
Ein nicht-parametrisches Modell zur Regression, das verwendet wird, um Vorhersagen mit Unsicherheitsabschätzungen zu machen.
Random Forest (RF):
Ein Ensemble-Lernverfahren, das viele Entscheidungsbäume trainiert und deren Ergebnisse kombiniert, um robustere und genauere Vorhersagen zu machen.
Große Sprachmodelle / Large Language Model (LLM):
Ein tiefes neuronales Netzwerk, das auf großen Mengen von Textdaten trainiert wurde und in der Lage ist, natürliche Sprache zu generieren, wie z. B. GPT-3.
Automatisiertes Maschinelles Lernen / Automated Machine Learning (AutoML):
Der Prozess der Automatisierung der Anwendung von maschinellem Lernen auf reale Probleme. AutoML umfasst die automatische Auswahl von Modellen, Hyperparametertuning und Modellbewertung.
SVM (Support Vector Machine):
Ein überwachter Lernalgorithmus, der sowohl für Klassifikations- als auch für Regressionsaufgaben verwendet wird und darauf abzielt, die bestmögliche Trennlinie (oder Hyperebene) zwischen Klassen zu finden.
k-NN (k-Nearest Neighbors):
Ein einfacher, nicht-parametrischer Algorithmus, der für Klassifikations- und Regressionsaufgaben verwendet wird und Vorhersagen auf Basis der K-ähnlichsten Datenpunkte im Trainingssatz trifft.
LSTM (Long Short-Term Memory):
Ein spezieller Typ von Rekurrenten Neuronalen Netzwerken (RNNs), der entworfen wurde, um das Problem des Langzeitgedächtnisses zu lösen. LSTMs können wichtige Informationen über lange Zeitspannen hinweg speichern und abrufen.
Hauptkomponentenanalyse / PCA (Principal Component Analysis):
Eine Technik zur Dimensionenreduktion, die darauf abzielt, die Varianz in einem Datensatz durch Transformation auf eine kleinere Anzahl von Dimensionen zu maximieren.
Entscheidungsbaum / Decision Tree:
Ein Modell, das Daten in Form eines baumartigen Diagramms darstellt und auf Basis von Entscheidungen (Knoten) und Resultaten (Blättern) Vorhersagen trifft. Häufig verwendet für Klassifikations- und Regressionsaufgaben.
AdaBoost / AdaBoost:
Ein Ensemble-Lernverfahren, das mehrere schwache Klassifikatoren kombiniert, um einen starken Klassifikator zu erstellen. Es gewichtet falsch klassifizierte Datenpunkte stärker, um die Modellgenauigkeit zu verbessern.
Gradient Boosting / Gradient Boosting:
Ein weiteres Ensemble-Lernverfahren, das sequentiell Modelle trainiert, wobei jedes Modell die Fehler der vorherigen Modelle korrigiert.
K-Means / K-Means:
Ein Algorithmus für unüberwachtes Lernen, der Daten in K-Cluster unterteilt, wobei jede Datenpunkt dem Cluster mit dem nächsten Mittelwert zugewiesen wird.
Hierarchisches Clustering / Hierarchical Clustering:
Ein unüberwachter Lernalgorithmus, der eine hierarchische Struktur von Clustern erstellt, indem er Datenpunkte schrittweise zusammenfasst oder teilt. Auf diese Weise werden Gruppen (Cluster) aus Daten gebildet, die sich in ihren Strukturen ähneln. Wie diese Ähnlichkeit genau definiert wird, ist dem Algorithmus überlassen.
Selbstaufmerksamkeit / Self-Attention:
Self-Attention ist ein Mechanismus, der beim maschinellen Lernen, insbesondere bei der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) und bei Computer-Vision-Aufgaben, verwendet wird, um Abhängigkeiten und Beziehungen in Eingabesequenzen zu erfassen. Es ermöglicht dem Modell, die Bedeutung verschiedener Teile der Eingabesequenz zu erkennen und zu gewichten, indem es sich selbst beobachtet.
Einbettungsschicht / Embedding Layer:
Eine Art von Hiddel Layer (versteckter Schicht) in einem neuronalen Netzwerk. Diese Art von Layer ordnet Eingabedaten von einem hochdimensionalen in einen niedrigdimensionalen Raum ein, wodurch das Netz mehr über die Beziehung zwischen den einzelnen Eingaben lernt und die Daten effizienter verarbeiten kann.
Eingabeschicht:
Die erste Schicht eines neuronalen Netzes, die die Eingabedaten entgegennimmt und an die nächsten Schichten weiterleitet. Sie repräsentiert die Rohdaten, die dem Modell zugeführt werden.
Ausgabeschicht:
Die letzte Schicht eines neuronalen Netzes, die das finale Ergebnis des Modells liefert, wie z.B. eine Klassifizierung oder eine Vorhersage.
Faltungsschichten (Convolutional Layers):
Schichten in einem neuronalen Netz, die Faltungsoperationen durchführen, um Merkmale aus den Eingabedaten zu extrahieren. Besonders wichtig in Convolutional Neural Networks (CNNs) für die Bildverarbeitung.
4. Daten und Vorverarbeitung
Datenverteilung:
Die Verteilung der Werte in einem Datensatz, die wichtige Informationen über die Struktur und das Verhalten der Daten liefert.
Latente Variablen:
Nicht direkt beobachtbare Variablen, die in einem Modell verwendet werden, um zugrunde liegende Strukturen oder Muster in den Daten zu repräsentieren.
Epoche / Epoch:
Ein vollständiger Durchlauf durch den gesamten Trainingsdatensatz während des Lernprozesses.
Batch-Größe / Batch Size:
Die Anzahl der Trainingsbeispiele, die in einer Iteration des Modelltrainings verwendet werden.
Eingabedaten / Features:
Eingaben (oder Merkmale) sind die Variablen oder Attribute, die zur Vorhersage verwendet werden. Beispielsweise könnten bei der Vorhersage von Hauspreisen die Merkmale die Größe, der Standort und die Anzahl der Schlafzimmer sein.
Beschriftete Daten / Labeled Data:
Dabei handelt es sich um Datensätze, die neben den Daten, die als Eingabedaten fungieren auch auch die entsprechende Ausgabe (Label) enthalten. Dies ist für das Training von überwachten Lernmodellen unerlässlich.
Ziele / Targets:
Die Ausgaben oder Labels, die das Modell vorhersagen soll. Zum Beispiel könnte bei einem Spam-Erkennungssystem das Ziel darin bestehen, festzustellen, ob eine E-Mail Spam ist oder nicht.
Lernrate:
Ein Hyperparameter, der die Schrittgröße steuert, mit der ein Modell seine Parameter während des Trainings anpasst. Eine zu hohe oder zu niedrige Lernrate kann die Leistung des Modells beeinträchtigen.
Hidden Layer:
Die Schichten in einem neuronalen Netzwerk, die zwischen der Eingabe- und der Ausgabeschicht liegen. Diese Schichten transformieren die Eingaben durch nicht-lineare Funktionen.
Synthetische Daten / Synthetic Data:
Künstlich erzeugte Daten, die zum Trainieren von Modellen verwendet werden. Synthetische Daten werden häufig dann verwendet, wenn echte Daten knapp oder sensibel sind. Synthetische Daten bergen aber auch ein gewisses Risiko was die Datenqualität angeht.
Datenaugmentation / Data Augmentation:
Techniken, die zur Erhöhung der Vielfalt der Trainingsdaten ohne Erhebung neuer Daten eingesetzt werden, oft durch Transformation vorhandener Daten, wie z. B. durch Rotieren von Bildern. Es werden also bestehende Daten verwendet und dann abgeändert, um dem Modell im Traning eine größere Varianz an Daten geben zu können.
Datenimputation / Data Imputation:
Der Prozess des Auffüllens fehlender Daten mit Ersatzwerten, um die Integrität eines Datensatzes zu erhalten.
Tokenisierung / Tokenization:
Der Prozess der Umwandlung von Text in kleinere Einheiten (Tokens), wie Wörter oder Unterwörter, zur Verarbeitung in NLP-Modellen. Texte werden also in kleinere Stücke unterteilt, um sie maschinell besser verarbeitbar zu machen.
Wort-Einbettung / Word Embedding:
Eine Darstellung von Text, bei der Wörter in Vektoren in einem kontinuierlichen Vektorraum abgebildet werden, um die semantische Bedeutung zu erfassen. Auf diese Weise können die Beziehungen von Wörtern wie Ähnlichkeit oder Zusammenhang abgebildet werden.
Selbstaufmerksamkeit (Self-Attention):
Ein Mechanismus, der es einem Modell ermöglicht, verschiedene Teile einer Eingabesequenz unterschiedlich zu gewichten, basierend auf ihrer Bedeutung. Dies ist zentral für Transformer-Modelle und ermöglicht es, komplexe Abhängigkeiten in den Daten zu erfassen.
Graphdaten:
Strukturelle Daten, die als Knoten und Kanten in einem Graphen dargestellt werden. Sie kommen oft in Netzwerken oder Beziehungen zwischen Entitäten vor und werden in Graph Neural Networks (GNNs) verarbeitet.
Datenkodierung:
Der Prozess der Umwandlung von Rohdaten in ein Format, das für maschinelle Lernmodelle geeignet ist. Dies kann die Transformation von kategorischen Daten in numerische Werte oder die Normalisierung von Daten umfassen.
Prompt:
Eine kurze Eingabe oder ein Text, der einem Modell gegeben wird, um eine spezifische Aufgabe auszuführen oder eine bestimmte Ausgabe zu erzeugen. In der Verarbeitung natürlicher Sprache ist der Prompt der Text, der die gewünschte Aktion auslöst.
Dimensionsreduktion:
Ein Verfahren, um die Anzahl der Zufallsvariablen unter Berücksichtigung der wichtigsten Informationen zu verringern. Methoden wie PCA (Principal Component Analysis) werden verwendet, um die Komplexität der Daten zu reduzieren.
5. Optimierung und Tuning
Optimierung / Optimization:
Der Prozess der Anpassung der Modellparameter zur Minimierung der Verlustfunktion, typischerweise durch Techniken wie den Gradientenabstieg.
Tuning:
Der Prozess der Anpassung der Hyperparameter eines Modells, um dessen Leistung zu optimieren.
Hyperparameter:
Einstellungen oder Konfigurationen, die vor Beginn des Trainingsprozesses festgelegt werden, wie z.B. die Lernrate oder die Anzahl der Schichten in einem neuronalen Netzwerk. Sie müssen feinjustiert werden, um die Modellleistung zu verbessern.
Metaparameter:
Hyperparameter, die die Konfiguration anderer Hyperparameter steuern. Sie werden oft verwendet, um den eigentlichen Tuning-Prozess der Hyperparameter zu variieren.
Gradientenabstieg / Gradient Descent:
Ein Optimierungsalgorithmus, der verwendet wird, um die Verlustfunktion zu minimieren, indem die Hyperparameter schrittweise angepasst werden.
Bayessche Optimierung / Bayesian Optimization:
Ein Ansatz zur Optimierung komplexer, teurer und nicht-linearer Funktionen, oft verwendet zur Feinabstimmung von Hyperparametern in maschinellen Lernmodellen.
Evolutionäre Algorithmen / Evolutionary Algorithms:
Optimierungstechniken, die von der natürlichen Evolution inspiriert sind und Mechanismen wie Mutation, Selektion und Kreuzung nutzen, um Lösungen für Probleme zu finden.
6. Evaluierung und Metriken
Metriken / Metrics:
Kennzahlen zur Bewertung der Leistung von Modellen, wie z. B. Genauigkeit, Präzision, Recall und F1-Score.
Verlust / Loss:
Ein Maß dafür, wie gut (oder schlecht) die Vorhersagen eines Modells mit den tatsächlichen Daten übereinstimmen. Ein niedrigerer Loss weist auf eine bessere Modellleistung hin.
Train/Test-Aufteilung / Train/Test Split:
Die Aufteilung eines Datensatzes in zwei Teile: einen zum Trainieren des Modells und einen zum Testen seiner Leistung. Dies hilft, die Fähigkeit des Modells zu bewerten, auf neue, unbekannte Daten zu verallgemeinern. Das heißt auf basis der Trainingsdaten lernt das Modell die Daten kennen und auf den Testdaten, die dem Modell unbekannt sind, wird überprüft, ob es tatsächlich allgemein gültige Muster gelernt hat.
Genauigkeit / Accuracy:
Eine Metrik, die den Prozentsatz aller korrekten Vorhersagen eines Modells von allen getätigten Vorhersagen angibt. Häufig bei Klassifikationsaufgaben verwendet. Also der Anteil aller Vorhersagen, die korrekt sind.
Präzision / Precision:
Eine Metrik, die den Anteil der tatsächlichen positiven Vorhersagen unter allen als positiv klassifizierten Vorhersagen des Modells angibt. Also wie viel Prozent der als positiv vorhergesagten Werte sind tatsächlich positiv.
Recall:
Eine Metrik, die den Anteil der tatsächlichen positiven Vorhersagen unter allen positiven Fällen in den Daten misst. Wie viel Pozent der positiven Fälle wurden also vom Modell richtig als positiv vorhergesagt.
F1-Score:
Eine Metrik, die Precision und Recall ausbalanciert und eine einzige Kennzahl liefert, die sowohl falsche Positive als auch falsche Negative berücksichtigt.
Überanpassung / Overfitting:
Eine Situation, in der ein Modell sehr gut auf Trainingsdaten performt, aber Schwierigkeiten hat, auf neue, ungesehene Daten zu generalisieren. Das heißt, dass das Modell sich zu stark an die Trainingsdaten angepasst hat und dementsprechend weniger gut auf davon abweichenden Testdaten performt.
Unteranpassung / Underfitting:
Wenn ein Modell zu einfach ist, um die zugrunde liegende Struktur der Daten zu erfassen, was zu einer schlechten Leistung sowohl auf Trainings- als auch auf Testdaten führt.
Regularisierung / Regularization:
Techniken, die verwendet werden, um Overfitting zu verhindern, indem eine Strafe in die Verlustfunktion aufgenommen wird, die das Modell davon abhält, zu komplex zu werden.
Kreuzvalidierung / Cros-Validation:
Eine Technik zur Bewertung der Modellleistung, indem Daten in mehrere Teilmengen unterteilt und das Modell auf unterschiedlichen Kombinationen dieser Teilmengen trainiert und getestet wird.
Unsicherheitsabschätzungen:
Methoden, die verwendet werden, um die Unsicherheit der Vorhersagen eines Modells zu quantifizieren. Diese sind wichtig für die Bewertung der Vertrauenswürdigkeit von Modellvorhersagen.
ROC-Kurve (Receiver Operating Characteristic):
Eine grafische Darstellung der Vorhersagekraft eines Modells, bei der die Rate der wahren Positiven gegen die Rate der falschen Positiven aufgetragen wird.
AUC (Area Under the Curve):
Die Fläche unter der ROC-Kurve, die als zusammenfassendes Maß für die Modellleistung verwendet wird.
Konfusionsmatrix / Confusion Matrix:
Eine Tabelle, die die tatsächlichen versus die vorhergesagten Klassifikationen eines Modells anzeigt und zur Berechnung von Metriken wie Accuracy, Precision, Recall und F1-Score verwendet wird.
Logarithmische Verlustfunktion / Log-Loss:
Eine Verlustfunktion, die in Klassifikationsproblemen verwendet wird, um die Unsicherheit der Vorhersagen zu messen. Sie wird insbesondere bei Wahrscheinlichkeitsausgaben verwendet.
7. Erklärbarkeit und Transparenz
Green AI (Grüne KI) / Green AI:
Ein Ansatz, der darauf abzielt, die Umweltbelastung durch KI-Entwicklung und -Einsatz zu minimieren. Dazu werden ressourceneffiziente Modelle und Algorithmen verwendet.
Fairness:
Im Kontext der KI bezeichnet ein Vorgehen bei dem darauf geachtet wird, dass KI-Systeme fair arbeiten. Das bedeutet, dsas die Systeme so trainiert werden, dass sie keine Voreingenommenheiten aufweisen und alle Nutzergruppen gerecht behandeltn. Dazu ist es wichtig zu wissen welche Gruppen es theoretisch gibt, um diese in den Trainingsdaten gleichberechtigt repräsentieren zu können.
Erklärbare KI / Explainable AI (XAI):
Der Bereich der KI, der sich mit der Entwicklung von Methoden beschäftigt, um die Entscheidungsfindung von KI-Systemen transparent und verständlich für Menschen zu machen. Dabei wird entgegen dem Black Box Prinzip versucht, KI-Systeme zu entwickeln, deren Entscheidungen transparent für den Nutzer sind, um so das Vertrauen, aber auch die Kontrolle zu erhöhen.
SHAP (SHapley Additive exPlanations):
Ein Verfahren zur Erklärbarkeit von Modellen, das auf den Shapley-Werten aus der Spieltheorie basiert und die Bedeutung jeder Eingabevariable für eine Vorhersage quantifiziert. Es wird also darstellbar gemacht, welche der Eingabedaten eine wie große Rolle für die Entscheidungsfindung spielen.
EU AI Act:
Ist eine Verordnung der Europäischen Union, die Regelungen für die Entwicklung, Bereitstellung und Nutzung von Künstlicher Intelligenz (KI) festlegt. Die Verordnung zielt darauf ab, das Vertrauen in KI-Systeme zu stärken, indem sie Sicherheits-, Transparenz- und Ethikanforderungen definiert.
Adversariale Angriffe / Adversarial Attacks:
Techniken, die darauf abzielen, maschinelle Lernmodelle durch speziell gestaltete Eingaben zu täuschen oder zu manipulieren, um fehlerhafte Vorhersagen zu erzeugen. Beispielsweise sind manche Bildklassifiaktionen anfällig dafür wenn einzelne Pixel verändert werden. Das ist für den Mensch nicht wahrnehmbar kann aber das Modell stark beeinflussen.
Voreingenommenheit / Bias:
Ein systematischer Fehler in den Vorhersagen eines Modells, der durch Vorurteile in den Trainingsdaten oder im Modell selbst verursacht wird und zu ungerechten oder diskriminierenden Ergebnissen führen kann. Mit Vorurteil sind dabei Strukturen in den Daten gemeint, die dazu führen, dass systematisch eine bestimmte Gruppe diskriminiert wird, weil sie z.B. unterrepräsentiert ist.
Robustheit / Robustness:
Die Fähigkeit eines Modells, stabile und verlässliche Vorhersagen zu treffen, auch wenn es mit unerwarteten oder verrauschten Daten konfrontiert wird.
8. Anwendungsgebiete
Gesichtserkennung / Facial Recognition:
Ein Bereich der Bildverarbeitung und Computer Vision, der es Systemen ermöglicht, Gesichter in Bildern oder Videos zu erkennen und zu identifizieren.
Sprachverarbeitung / Speech Processing:
Die Anwendung von KI-Techniken auf Sprachdaten, um Aufgaben wie Sprachtranskription, Spracherkennung und Sprachsynthese durchzuführen.
Empfehlungssysteme / Recommendation Systems:
Systeme, die personalisierte Empfehlungen basierend auf dem Verhalten und den Vorlieben der Nutzer bereitstellen, z. B. in Online-Shops oder Streaming-Diensten.
Objekterkennung:
Ein Computer-Vision-Aufgabenfeld, bei dem ein Modell darauf trainiert wird, spezifische Objekte in Bildern zu identifizieren und zu lokalisieren.
Bildsegmentierung:
Ein Prozess in der Bildverarbeitung, bei dem ein Bild in seine konstituierenden Teile oder Regionen unterteilt wird, oft um Objekte oder Strukturen im Bild zu identifizieren.